这是《opencv2.4.9tutorial.pdf》的objdetect module的唯一一个例子。
在中进行人脸或者人眼 或者身体的检测 首先就是训练好级联分类器,然后就是检测就行。在中,“opencv/sources/data中就有内置训练好的:基于haar特征的级联分类器、基于hog特征的级联分类器、基于lbp特征的级联分类器”三种。相比较来说 算haar文件夹中的分类器最多,其他两个比如:hog的只有一个行人检测分类器“hogcascade_pedestrians.xml”而已;
lbp的有三个分类器:“lbpcascade_frontalface.xml”、“lbpcascade_profileface.xml”、“lbpcascade_silverware.xml”。·
采用的是级联分类器类:CascadeClassifier,并通过不同的分类器类型进行初始化。
1、先设定不同的分类器:
这里使用自带的haar特征的前人脸和眼睛级联分类器:
string face_cascade_name = "haarcascade_frontalface_alt.xml"; string eyes_cascade_name = "haarcascade_eye_tree_eyeglasses.xml";
2、然后进行分类器类的初始化:
CascadeClassifier face_cascade; CascadeClassifier eyes_cascade;
if( !face_cascade.load( face_cascade_name ) ){ printf("--(!)Error loading\n"); return -1; }; if( !eyes_cascade.load( eyes_cascade_name ) ){ printf("--(!)Error loading\n"); return -1; }; 这里使用load()函数进行加载,当然也可以定义类的对象的时候进行初始化。load()函数的返回值是bool类型。
当不需要该分类器可以使用cvReleasehaarClassifierCascade(&cascade);进行释放。
3、进行对象的检测
void CascadeClassifier::detectMultiScale(const Mat& image, vector<Rect>& objects, double scaleFactor=1.1, int minNeighbors=3, int flags=0,
Size minSize=Size(), Size maxSize=Size())这是这个函数的原型,是用来在输入图像中检测不同尺寸的对象,检测的对象将会作为一个矩形列表,也就是原型中的第二个参数。
参数列表:需要检测的图像(矩阵的类型为CV_8U)、矩形vector容器用来装填所包含的检测到的对象、在每个图像尺度上需要进行缩放的因子、候选矩形框所需要包含的邻居大小、已经废弃的参数、可能的对象尺寸的最小值、可能的对象的尺寸的最大值;
最后两个参数就是用来控制范围的,使得能够忽略小于最小的和大于最大的;第一个参数的要求是灰度图像,所以不能是彩色,需要进行转换:
vectorfaces; Mat detFrame_gray; cvtColor( srcFrame, detFrame_gray, CV_BGR2GRAY ); equalizeHist( detFrame_gray, detFrame_gray );
face_cascade.detectMultiScale( detFrame_gray, faces, 1.1, 2, 0|CV_HAAR_SCALE_IMAGE, Size(30, 30) );
上面就是会自动检测人脸然后将检测到的人脸的个数和每个人脸的矩形区域放在faces这个容器类中。上面最后一个最大值未指定大小,只设定了最小的对象矩形大小。
for( int i = 0; i < faces.size(); i++ ) { Point center( faces[i].x + faces[i].width*0.5, faces[i].y + faces[i].height*0.5 ); ellipse( frame, center, Size( faces[i].width*0.5, faces[i].height*0.5), 0, 0, 360, Scalar( 255, 0, 255 ), 4, 8, 0 ); Mat faceROI = frame_gray( faces[i] ); vector eyes; //-- 在每张人脸上检测双眼 eyes_cascade.detectMultiScale( faceROI, eyes, 1.1, 2, 0 |CV_HAAR_SCALE_IMAGE, Size(30, 30) ); for( int j = 0; j < eyes.size(); j++ ) { Point center( faces[i].x + eyes[j].x + eyes[j].width*0.5, faces[i].y + eyes[j].y + eyes[j].height*0.5 ); int radius = cvRound( (eyes[j].width + eyes[i].height)*0.25 ); circle( frame, center, radius, Scalar( 255, 0, 0 ), 4, 8, 0 ); } } 上面通过对每个人脸中,先定位好每个人脸的中心位置,然后在采用画椭圆的方式来讲人脸进行框出来,并且对每个框出来的位置进行选取ROI感兴趣区域来检测眼睛。并将检测到的眼睛用圆框出来。
notes:不论是上面的人脸还是眼睛检测,其中的第一个参数都是被检测的图像,而且在后面的画椭圆和圆的过程中第一个参数仍然是原图像,最后加个imshow()的函数就可以进行显示检测到的结果。
其中的cvRound()函数的原型为 int cvRound(double value);将参数转化成与其最接近的整数。
下面这部分来自于http://blog.csdn/vsooda/article/details/7543789
但是也和《opencv2.4.9refman.pdf》的448页一样,相信该作者也是翻译过来的。
目前人脸检测分类器大都是基于haar特征利用Adaboost学习训练的。
目标检测方法最初由Paul Viola [Viola01]提出,并由Rainer Lienhart [Lienhart02]对这一方法进行了改善. 首先,利用样本(大约几百幅样本图片)的 harr 特征进行分类器训练,得到一个级联的boosted分类器。训练样本分为正例样本和反例样本,其中正例样本是指待检目标样本(例如人脸或汽车等),反例样本指其它任意图片,所有的样本图片都被归一化为同样的尺寸大小(例如,20x20)。
分类器训练完以后,就可以应用于输入图像中的感兴趣区域(与训练样本相同的尺寸)的检测。检测到目标区域(汽车或人脸)分类器输出为1,否则输出为0。为了检测整副图像,可以在图像中移动搜索窗口,检测每一个位置来确定可能的目标。 为了搜索不同大小的目标物体,分类器被设计为可以进行尺寸改变,这样比改变待检图像的尺寸大小更为有效。所以,为了在图像中检测未知大小的目标物体,扫描程序通常需要用不同比例大小的搜索窗口对图片进行几次扫描。
分类器中的“级联”是指最终的分类器是由几个简单分类器级联组成。在图像检测中,被检窗口依次通过每一级分类器, 这样在前面几层的检测中大部分的候选区域就被排除了,全部通过每一级分类器检测的区域即为目标区域。 目前支持这种分类器的boosting技术有四种: Discrete Adaboost, Real Adaboost, Gentle Adaboost and Logitboost。"boosted" 即指级联分类器的每一层都可以从中选取一个boosting算法(权重投票),并利用基础分类器的自我训练得到。基础分类器是至少有两个叶结点的决策树分类器。 Haar特征是基础分类器的输入,主要描述如下。目前的算法主要利用下面的Harr特征。
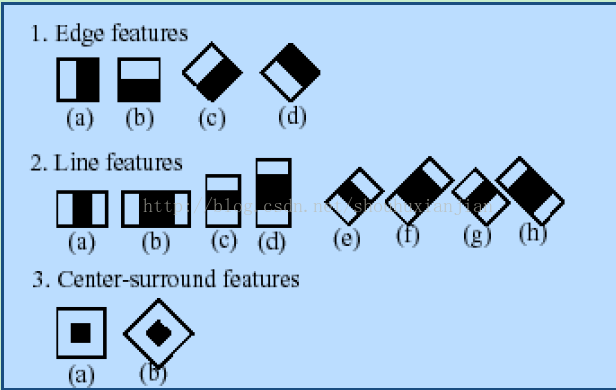
个人:其实过程就是这样,如果感兴趣,更多的应该是使用自己训练的分类器,在目标检测这部分中,暂时只介绍了级联分类器类,在《opencv2.4.9refman》中还介绍了潜在SVM分类器,不过还没有对应的例子罢了。